先随便扯扯。对于当前的 WEB 而言,html 是联系大多数 Web 资源的纽带,也是内容的载体。在 Web 被刚刚设计出来的时候,Tim Berners-Lee 可能不会想到它现在会达到的规模以及深入到我们生活的那么多方面。也许起初的想法很简单:用来发布 Web 内容和资源的索引,方便人们查看。
但是随着 Web 规模的不断扩大,信息量之大已经不在人肉处理的范围之内了。这个时候人们开始用机器来处理 Web 上发布的各种内容,搜索引擎就诞生了。再后来,人们又设计了各种智能程序来对索引好的内容作各种处理和挖掘。所以让机器能够更好地读懂 Web 上发布的各种内容就变得越来越重要。
其实 HTML 在刚开始设计出来的时候就是带有一定的「语义」的,包括段落、表格、图片、标题等等,但这些更多地只是方便浏览器等 UA 对它们作合适的处理。但逐渐地,机器也要借助 HTML 提供的语义以及自然语言处理的手段来「读懂」它们从网上获取的 HTML 文档,但它们无法读懂例如「红色的文字」或者是深度嵌套的表格布局中内容的含义,因为太多已有的内容都是专门为了可视化的浏览器设计的。面对这种情况,出现了两种观点:我们可以让机器的理解能力越来越接近人类,人能看懂、听懂的东西,机器也能理解;
我们应该在发布内容的时候,就用机器可读的、被广泛认可的语义信息来描述内容,来降低机器处理 Web 内容的难度(HTML 本身就已经是朝这个方向迈出的一小步了)。
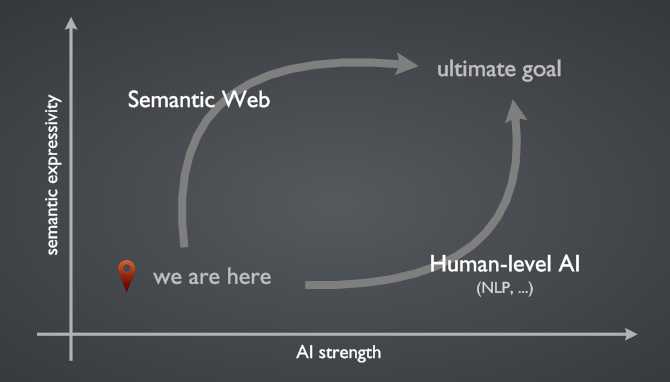
我认为我们当前能够看得见摸得着的 Web 语义化,其实就是在往第二条路的方向上,迈出的一小步,即对已经有的被广泛认可的 HTML 标准做改进。我们刚开始意识到,我们必须回归内容本身,将内容本身的语义合理地表述出来,再为不同的用户代理设计不同的样式描述,也就是我们说的内容与样式分离。这样我们在提供内容的时候,首先要做的就是将内容本身进行合理的描述,暂时不用考虑它的最终呈现会是什么样子。
HTML 规范其实一直在往语义化的方向上努力,许多元素、属性在设计的时候,就已经考虑了如何让各种用户代理甚至网络爬虫更好地理解 HTML 文档。html5 更是在之前规范的基础上,将所有表现层(PResentational)的语义描述都进行了修改或者删除,增加了不少可以表达更丰富语义的元素。为什么这样的语义元素是有意义的?因为它们被广泛认可。所谓语义本身就是对符号的一种共识,被认可的程度越高、范围越广,人们就越可以依赖它实现各种各样的功能。
HTML5 并非 Web 语义唯一倚仗的规范,除了 W3C 和 WHATWG 外,还有其它的组织在为扩展、标准化 Web 语义做着贡献。只要有浏览器厂商、搜索引擎原意支持,它们的规范一样可以成为通用的基础设施。例如 microFORMats 社区以及 http://Schema.org 上都有对 HTML 以及 Microdata(HTTP://www.w3.org/TR/Html5/microdata.html) 规范的扩展词汇表,google、Bing、Yahoo! 等搜索引擎以及各个主流浏览器都不同程度地接纳了其中定义的语义扩展,并应用在了生产中。





网友评论文明上网理性发言已有0人参与
发表评论: